
Externalize the configuration of the Jenkins Pipeline flow
/ 4 min read
Today, I would like to share with you how I’ve done my Jenkins Pipeline flow configuration to allow the developers to do environments reservation, to be more flexible at pipeline changes and, most of all, apply those changes faster to all collaborators on the project.
Before starting to explain how I’ve done the setup, you must know that I’m using a Jenkinsfile at the root of my project to be able to get the following benefices, as stated on the Jenkins website:
- Code review/iteration on the Pipeline
- Audit trail for the Pipeline
- Single source of truth for the Pipeline, which can be viewed and edited by multiple members of the project.
Generally, one of the caveat from using an external configuration was effectively to lose all of the above benefices. This is why I’ve externalized the configuration inside another repository on GitHub! This way, I’m able to track the changes, make use of reviews and keeping only one source of truth.
The goals
- Offering flexibility in our pipeline
- Providing pipeline changes faster to all branches of the repository
- Allowing environment reservation without any fancy tools to the developers
- Tracking of the changes done to the pipeline
- A fast way to know who is using which environment
- Easily separate the feature branches, where the devs are mostly working, from our integration and production branches used for packaging purposes.
Show me the code!
Ok ok, it’s time to have a look at that extremely well-commented😉 file:
Now it’s time to look at our external configuration hosted in another repository on GitHub.
I don’t think that the previous files need more explanation than the ones already embedded inside it, but if you feel that you need more precision, don’t hesitate to post your questions.
Let’s see the result
To make that story more visual, I added some captures of the resulting of the different configurations of our Jenkins Pipeline. Let’s take a look at each of those.
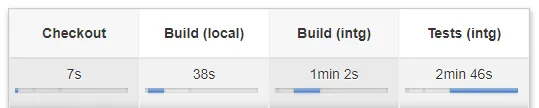
Pipeline of a Feature branch (line 99)
This is the default configuration returned when there is no match with the branch name in our mapping file. You may want to take a look at line 127 from the mapping file and line 64 of the Jenkinsfile to have a better understanding of that mechanism. So, every time a developer creates or push changes to their feature branch Jenkins is running that pipeline.
I’ve taken the occasion to create some sort of triggers inside our pipeline to update some statuses check on GitHub to help us with Pull Request reviews… but, it’s for another story that, I promise, I’m gonna take the time to write😀. (update: Thing promised, thing due!)
Ok ok, what about the sandboxes environments?

Pipeline of a feature branch linked to a Sandbox (line 14 and 46)
Nothing too complicated here, this is the same as the previous pipeline with a slight difference, the branch is linked to an environment to allow testers to play with some new functionalities before going into our integration pipeline for regression testing and other robust testing processes. By doing so, I’m enabling the developers and testers to be able to own a specific environment with a kind of reservation system. Nothing too fancy or time-consuming and with a tool they like!
Talking of the integration pipeline, let’s introduce the masterpiece.

Pipeline of the Integration branch (line 75)
Yep, I know, this one is huge, but this is where we can see the force of our mapping configuration allowing us to target multiple environments with different specificity and to make adjustments easily as required and requested without too much hassle.
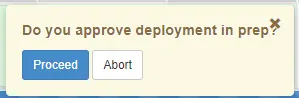
Approval before deployment
To avoid rebuilding an environment currently used by one of the team’s resources, I’ve added an option to request approval before launching the deployment. Greatly appreciated by the team 😇.
I’m sure you saw that last one coming, let’s talk about the production pipeline.
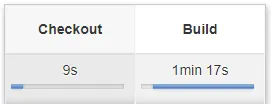
Pipeline of the Master branch (line 62)
As of now, I’m not using Jenkins to perform the deployment in production, sure, I could simply add the “deploy” stage to my configuration for that specific environment and the job will be done in a second.
But there is a time for everything and it’s not the time for that improvement. This is one of my next targets… this and sharing other stories with you of course 😉. Let’s use the “archive” option (line 71) and keep that archive for manual deployment in production!